
Alla scoperta delle norme dedicate all’intelligenza artificiale
Questa newsletter si propone di esaminare il Regolamento Europeo in materia di Intelligenza Artificiale con brevi articoli settimanali (in uscita il venerdì).
La prima uscita è disponibile qui: https://studiolegalebroglia.com/2024/05/17/frid_ai_news-00/.
Le definizioni in materia di AI
Se nella scorsa uscita ci siamo occupati di diverse definizioni che il Regolamento propone in relazione alla biometria, oggi ci occupiamo di approfondire qualche concetto in materia di Intelligenza Artificiale, perché l’art. 3 dell’AI Act, come abbiamo visto, ne contiene diverse e, ovviamente, molte di queste definizioni si riferiscono a sistemi e modelli di Intelligenza Artificiale.
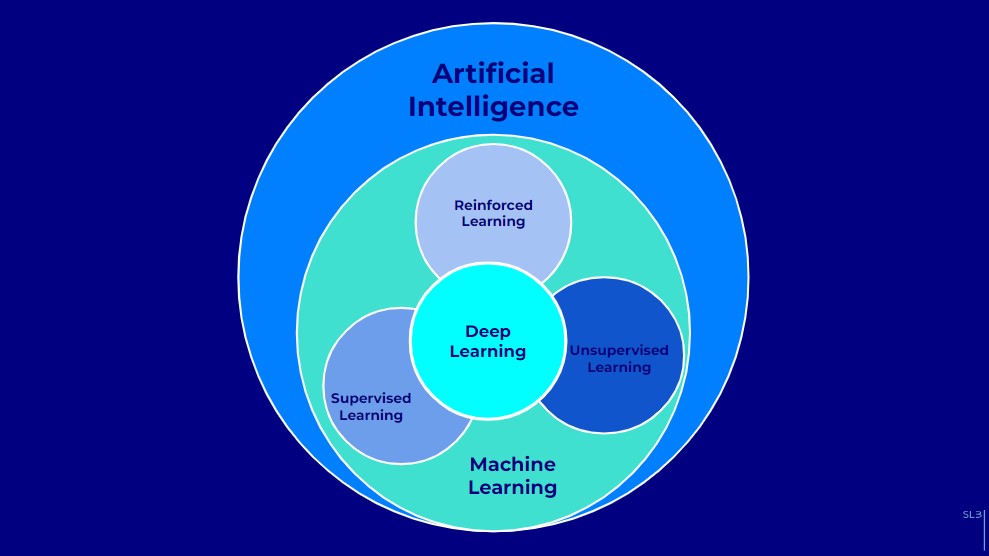
Intelligenza Artificiale
L’intelligenza artificiale è, come noto e come abbiamo già visto, un settore dell’informatica che si occupa in particolare della ricerca e dello sviluppo di meccanismi e di applicazioni di sistemi di AI (cfr. anche ISO IEC 22989:2022, che si occupa in modo dettagliato della terminologia e delle definizioni nel campo dell’IA).
Sono sistemi informatici capaci di svolgere compiti che richiederebbero l’intelligenza umana, come il riconoscimento di immagini, la comprensione del linguaggio, la presa di decisioni, l’apprendimento automatico.
Utilizzano algoritmi e modelli matematici per elaborare dati, apprendere da essi e prendere decisioni autonome.
Machine Learning
Il Machine Learning (ML) è un sottocampo dell’intelligenza artificiale che si concentra sullo sviluppo di algoritmi e modelli statistici che permettono ai computer di imparare dai dati e fare previsioni o prendere decisioni basate sui dati.
Gli algoritmi di ML costruiscono un modello matematico basato su dati di addestramento per fare previsioni o prendere decisioni senza essere esplicitamente programmati per svolgere il compito specifico.
Il ML è dunque un sottoinsieme dell’IA: una tecnologia che consente ai sistemi informatici di apprendere e migliorare automaticamente dalle esperienze passate senza essere esplicitamente programmati. Viene utilizzato in vari settori per analizzare grandi quantità di dati, individuare modelli e tendenze, fare previsioni e supportare decisioni automatiche.
ML supervisionato
Il Machine Learning supervisionato è un tipo di apprendimento automatico in cui il modello viene addestrato su un set di dati etichettati.
Ogni esempio nel set di dati di addestramento ha una coppia input-output, dove l’output è un’etichetta che indica il risultato desiderato.
ML non supervisionato
Il Machine Learning non supervisionato è un tipo di apprendimento automatico in cui il modello viene addestrato su un set di dati non etichettati: l’obiettivo è quello di trovare strutture o pattern nei dati senza avere un output noto o etichettato.
L’etichettatura
L’etichettatura, quindi, nel ML supervisionato, è essenziale per l’apprendimento: le etichette forniscono la “verità” necessaria affinché il modello impari a fare previsioni corrette.
Spesso la creazione di set di dati etichettati richiede un notevole sforzo umano per annotare correttamente ogni esempio.
D’altra parte, l’assenza di etichettatura nel ML non supervisionato permette di analizzare grandi volumi di dati senza la necessità di etichettature dettagliate ed è utile per scoprire pattern nascosti e “percorsi” che potrebbero non essere evidenti a priori.
Possiamo, sostanzialmente, dire che nel ML non supervisionato, anziché prima del processo di trattamento, l’etichettatura viene utilizzata dopo, a risultato ottenuto.
Il rinforzo
Introduciamo, poi, in modo estremamente semplice, il concetto di “rinforzo”, che si riferisce a come un sistema apprende tramite premi o punizioni in base alle azioni che compie, migliorando le sue decisioni per ottenere il massimo beneficio possibile nel lungo termine.
Deep Learning
Il Deep Learning (DL) è un ulteriore sottocampo del Machine Learning: utilizza reti neurali artificiali con molti strati (profondi) per modellare e risolvere problemi complessi.
Queste reti neurali profonde sono progettate per apprendere rappresentazioni gerarchiche dei dati attraverso vari livelli di astrazione, permettendo al sistema di riconoscere pattern complessi e fare previsioni accurate.
Il DL è particolarmente efficace in compiti come il riconoscimento di immagini, la traduzione automatica, e l’elaborazione del linguaggio naturale.
Come funziona l’AI
Vediamo, molto in sintesi, come funziona un sistema, un modello, un processo di intelligenza artificiale.
- Raccolta dei dati: i sistemi di AI richiedono una grande quantità di dati per imparare. Questi dati possono provenire da diverse fonti come database, sensori, internet, possono ovviamente essere anche dati generati dagli utenti. È, evidentemente, essenziale che essi siano di qualità e pertinenti al compito che il sistema dovrà svolgere.
- Pre-elaborazione: una volta raccolti, i dati devono essere puliti e preparati per l’uso. Si procede con la rimozione di rumore, ossia si eliminano le interferenze per far sì che i sistemi AI “vedano” (o sentano 😁) meglio e prendano decisioni più accurate; si gestiscono i valori mancanti, la normalizzazione e la trasformazione dei dati in un formato utilizzabile per l’algoritmo di apprendimento.
- Selezione del modello: lo sviluppatore sceglie l’algoritmo o il modello da utilizzare a seconda del tipo di problema da risolvere (regressione, classificazione, clustering) e dalle caratteristiche dei dati.
- Il modello viene addestrato: si utilizzano i dati pre-elaborati, ottimizzando i “pesi” per minimizzare l’errore tra le previsioni del modello e i valori reali.
- Validazione e test: una volta addestrato, il modello deve essere validato e testato su set di dati separati. La validazione aiuta a regolare i parametri del modello, mentre il test verifica le prestazioni finali del modello.
- Dopo il processo di addestramento e validazione, il modello è pronto per l’inferenza. In questa fase, il modello utilizza i nuovi dati in tempo reale per fare previsioni o prendere decisioni basate sul modello addestrato. Si tratta di una fase fondamentale, perché il modello “addestrato” viene messo alla prova con nuovi dati, non utilizzati prima: l’obiettivo è quello di verificare l’utilizzo delle conoscenze acquisite per fare previsioni o prendere decisioni.
- Monitoraggio e Manutenzione, attività necessarie per garantire che funzioni correttamente nel tempo.
Le definizioni del Regolamento
Vediamo, ora, le specifiche definizioni contenute nell’Articolo 3, che corrispondono a quanto abbiamo visto sopra.
Dati di addestramento: i dati utilizzati per addestrare un sistema di IA adattando i parametri che può apprendere.
Dati di convalida: i dati utilizzati per fornire una valutazione del sistema di IA addestrato e per metterne a punto, tra l’altro, i parametri che non può apprendere e il processo di apprendimento, al fine … di evitare lo scarso (underfitting) o l’eccessivo (overfitting) adattamento ai dati di addestramento.
Set di dati di convalida: un set di dati distinto o costituito da una partizione fissa o variabile del set di dati di addestramento.
Dati di prova: i dati utilizzati per fornire una valutazione indipendente del sistema di IA al fine di confermare le prestazioni attese prima della sua immissione sul mercato o messa in servizio.
Dati di input: i dati forniti a un sistema di IA o direttamente acquisiti dallo stesso, in base ai quali il sistema produce un output.
E’ importante avere una certa comprensione della terminologia relativa all’intelligenza artificiale, così come esaminare le diverse definizioni che il Regolamento pone a base delle disposizioni. Senza di esse incorreremmo, come vedremo, in più di un fraintendimento.
Ma per oggi basta! Ci vediamo alla prossima.
p.s.: ogni suggerimento o correzione, come sempre, è più che ben accetta!
👾 👾 👾 👾 👾
Questa newsletter si propone di esaminare le principali disposizioni in arrivo con un linguaggio semplice e chiaro, accompagnato il più possibile da esempi concreti.
Se sei interessato, iscriviti. 👾