
Qualche giorno fa ho avuto l’opportunità di tenere una sessione di formazione in materia di sicurezza e protezione dei dati in una grande azienda che si occupa, tra altre cose, di sviluppo, gestione e manutenzione di software e applicativi.
Il confronto tra legali e tecnici, sviluppatori, gestionali, IT in generale, è talvolta un po’ impermeabile, nel senso che si fatica a comprendere le ragioni gli uni degli altri, quasi che si “viva” su piani diversi, incomunicabili.
Se è vero che ci sono differenti impostazioni e modi di pensare, tuttavia, ho sempre trovato di grande interesse cercare di comprendere di più il lato tecnico di quelli che sono mezzi e strumenti che permeano la nostra vita, tutti i giorni e sotto tanti aspetti.
Penso, poi, che sia oggi imprescindibile portare avanti un progetto di sviluppo che sia necessariamente in linea con le ormai tante norme che si rivolgono nello specifico ai prodotti e servizi digitali.
Le reazioni e le interazioni durante e al termine del “corso” sono state molto positive e mi fa piacere che qualcuno (così mi è stato detto) che aveva cercato ogni appiglio per non partecipare a una mattinata che pensava noiosa 😁, si sia ricreduto.
Il mondo è cambiato e continuerà a farlo. Sta a noi comprendere come funziona e come gestirlo, senza inutili pregiudizi.
Qui di seguito, oltre a qualche immagine tratta dalle slide utilizzate, alcune considerazioni generali, approfondite nel corso dell’evento.

Introduzione
Negli ultimi anni e ancor più in seguito alla pandemia, gli attacchi informatici sono cresciuti moltissimo.
Spesso gli obiettivi di tali attacchi, siano essi opportunistici o mirati, sono le vulnerabilità applicative.
Alla correzione dei difetti funzionali e di performance, ormai da anni, si accompagna una maggiore attenzione allo sviluppo sicuro di codice.
L’adozione di un modello di sviluppo sicuro, oltre ad abbassare in modo esponenziale gli eventuali costi di rimedio (più tardi vengono rilevate le vulnerabilità maggiore è il costo per porvi rimedio) è anche necessaria per evitare la violazione di norme generali e di settore, eventuali responsabilità legali o contrattuali, problemi reputazionali e di business.
Introduzione
Sviluppare e gestire applicazioni in modo sicuro e secondo le norme
Tutelare i segreti aziendali
Le tutele contrattuali “interne”
Le tutele contrattuali verso i terzi
Il Cloud e in generale la supply chain
Metodologie di sviluppo sicuro
Software Development Life Cycle
Evitare e mitigare gli errori
Change and Configuration Management
L’approccio DevOps
Le API
Code Repositories
SLA Service Level Agreements
Sviluppare in conformità al Gdpr
Premesse
Indicazioni sempre valide
Dati personali
Anonimizzazione e Pseudonimizzazione
Preparare il progetto
Metodologie di sviluppo sicure
Sicurezza dell’ambiente di sviluppo
Gestione e protezione del codice sorgente
Componenti di terze parti
Architettura e scelte
Proteggere i siti web, le applicazioni, i server
Tenere a mente i principi privacy
Informare gli utenti
Basi giuridiche e diritti
Sviluppare e gestire l’esercizio dei diritti
I cookie e gli analytics
Google Analytics
L’indirizzo IP è un dato personale?
Sviluppare e gestire applicazioni in modo sicuro e secondo le norme
Tutelare i segreti aziendali
Ogni azienda dovrebbe innanzitutto, per mantenere il proprio know-how, predisporre in via preventiva un insieme di misure di diversa natura, come ad esempio:
- Accordi di riservatezza o di segretezza (NDA);
- Patti di non concorrenza;
- Misure fisiche per prevenire intrusioni o accessi indesiderati o illeciti (videosorveglianza, porte blindate, controlli degli accessi, ecc.);
- Misure organizzative come policy, procedure, protocolli adeguatamente formulate e periodicamente verificate;
- Misure tecnologiche di varia natura (password, MFA, ecc.).
Esistono poi, ovviamente, le tutele apprestate da diverse disposizioni normative:
- Il codice della proprietà industriale;
- Gli obblighi di fedeltà del codice civile e i patti di non concorrenza;
- Diverse norme generali (Gdpr) o di settore (ad es.: NIS 2, normative dei settori bancari e finanziari, ecc.).
Le tutele contrattuali “interne”
Le principali tutele contrattuali possono essere:
- Il patto di non concorrenza (Artt. 2125 per il lavoratore e 2596 c.c. per le aziende);
- Gli NDA per le fasi precontrattuali;
- Gli accordi di riservatezza relativi allo svolgimento e alla fine dei rapporti di business;
- Il patto di non sollecitazione;
- Alcune clausole derivanti dalla normativa data protection;
- Il contratto di escrow;
- Diverse forme di cessione dei diritti o di licenza;
- Contratti tipicamente “cybersec” come quelli relativi all’esecuzione di Vulnerability Assessment e Penetration Test.
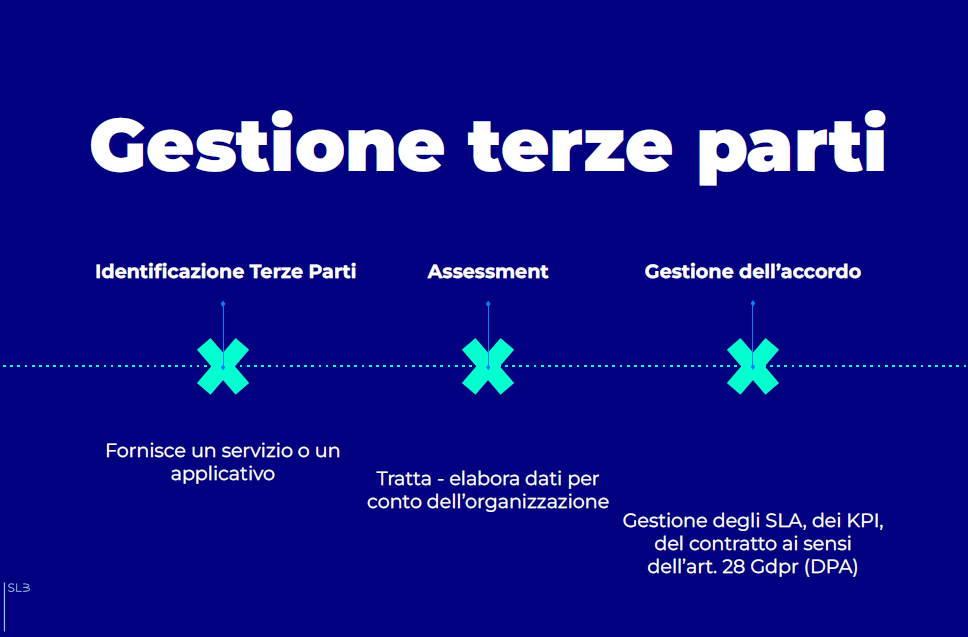
Le tutele contrattuali verso i terzi
Una delle principali forme di tutela aziendale verso soggetti terzi è data da un’attenta modulazione delle clausole contrattuali.
Il settore IT è, evidentemente, uno dei campi di elezione per la predisposizione dei cc.dd. SLA, i Service Level Agreement.
Si tratta di strumenti di definizione e valutazione delle esigenze di una organizzazione in termini di servizi richiesti, in termini di continuità, di efficacia, di efficienza.
Altre tutele sono imposte come obbligatorie dalle norme, come avviene per la gestione dei fornitori (cc.dd. Responsabili del trattamento) da parte del Gdpr: l’Art. 28 è molto specifico in merito a quanto deve essere precisato e richiesto, da parte di un’organizzazione, ogni qualvolta essa affidi determinate operazioni di trattamento ad un soggetto esterno.
Entrano in gioco, in questo caso, regimi di responsabilità condivisa, ma anche necessità congiunte di gestione della sicurezza, oltre che profili sanzionatori da non sottovalutare.
La gestione del soggetto terzo (fornitore, provider, altro elemento della supply chain) è rilevante anche dal punto di vista gestionale, oltre che per i profili già indicati: il Gdpr impone una attenta preselezione dei propri fornitori, di modo che sia possibile dimostrare e documentare, nell’ottica dell’accountability che permea il Regolamento, una selezione accurata.
Il Cloud e in generale la supply chain
L’ormai massiccio ricorso al cloud, nelle sue varie forme, apporta alla gestione delle forniture ulteriori questioni.
Spesso, infatti, nella contrattualistica cloud si ritrovano differenze importanti rispetto a contratti più “classici”, perché si tratta, in definitiva, di contratti di appalto di servizi, più che di eventuali licenze d’uso, manutenzione di licenze, approvvigionamento di hardware, personalizzazione di servizi, assistenza e manutenzione e così via.
Ne deriva l’importanza, per ogni organizzazione che vi faccia ricorso, di comprendere la disponibilità e l’accessibilità dei servizi (SLA), delle garanzie contrattuali sotto il profilo della sicurezza, la limitata o più spesso nulla negoziabilità delle condizioni contrattuali, la presenza di condizioni e clausole chiaramente orientate a favore del provider e così via.
In altre parole: mentre la contrattualistica tradizionale è, in un certo senso, ricamabile sulle specifiche necessità del caso, con il cloud il cliente deve, in fin dei conti, accettare un servizio così com’è.
La gestione della supply chain, inoltre, comporta rischi di varia natura.
Se con determinati provider è pressoché impossibile distaccarsi da forme e regolamentazioni già predisposte, dall’altro, con molteplici fornitori, le circostanze di possibile rischio aumentano in modo esponenziale: nessuno, oggi, “si fa in casa tutto da solo”.
L’azienda deve quindi, non solo perché per certi versi tenuta da specifiche normative, ma anche per la propria tutela, determinare con ciascuno dei fornitori rilevanti gli aspetti più importanti dei vari rapporti, che per esempio possono riguardare circostanze come:
- le criticità insite in ciascun contratto o posizione del fornitore;
- gli eventuali rischi derivanti dalla possibile indisponibilità dei servizi:
- i rischi derivanti da possibili attacchi cyber alla catena che si ripercuotano sull’azienda;
- i diritti di possibili modifiche alle pattuizioni;
- i livelli di servizio, come sempre;
- le eventuali penali;
- i downtime;
- le responsabilità;
- gli audit, ecc..

Metodologie di sviluppo sicuro
Lo sviluppo di software è un compito sfidante e complesso, preso in carico da sviluppatori con differenti livelli di competenza e di consapevolezza dei problemi di sicurezza.
Le applicazioni e i servizi spesso trattano dati di particolare delicatezza o appartenenti a soggetti di settori specificamente regolati.
Gli applicativi possono comportare significativi rischi per la gestione delle imprese e gli specialisti di sicurezza devono saper conoscere e comprendere questi rischi, bilanciarli con i requisiti di business e mettere in atto appropriate misure di mitigazione.
Le metodologie di sviluppo sicuro hanno la finalità di prevenire ed evitare l’inserimento accidentale di vulnerabilità di sicurezza nel codice, che le ricerche hanno dimostrato dipendere da un numero limitato di comuni errori di programmazione.
Software Development Life Cycle
Il criterio con il quale una metodologia di sviluppo o un modello di processo scompongono l’attività di realizzazione di applicazioni software in sottoattività fra di loro coordinate viene definito ciclo di vita del software.
Tendenzialmente tutti i modelli di sviluppo prevedono le seguenti fasi:
- Analisi,
- Progettazione,
- Sviluppo,
- Test,
- Manutenzione.
I più conosciuti e utilizzati sistemi di sviluppo sono, come noto:
- SSDLC Secure Software Development Life Cycle, ciclo di sviluppo sicuro del sw finalizzato a considerare e implementare le opportune finalità di sicurezza nel corso di tutte le fasi;
- il Microsoft Security Development Lifecycle (SDL), un rigoroso processo di programmazione sicura che ha notevolmente diminuito la presenza di vulnerabilità da quando è stato adottato;
- il modello CLASP nell’ambito di OWASP (Open Web Application Security Project), che da un approccio strutturato all’integrazione di attività di sicurezza all’interno di ogni fase di un normale ciclo di sviluppo;
- l’SSE-CMM, System Security Engineering – Capability Maturity Model, standard di fatto del settore, utilizzabile per migliorare e valutare la capacità di ingegnerizzazione con aspetti di sicurezza, all’interno di un’organizzazione. Deriva dal CMMI, Capability Maturity Model Integration, uno standard dei requisiti di sviluppo aziendali;
- SAMM, Software Assurance Maturity Model, un framework open sviluppato per supportare le organizzazioni nella formulazione di strategie relative alla sicurezza del sw;
- Agile, più una filosofia che un vero e proprio modello, molto utilizzato per via dei suoi “sprint” successivi, composti di plan, design, develop, test, deploy, review successivi.
Evitare e mitigare gli errori
Senza alcuna pretesa di completezza, qui di seguito alcune modalità per prevenire e ridurre la possibilità di commettere errori nello sviluppo di software:
- Input validation
- Autenticazione e Session Management
- Error handling
- Logging
- Fail secure e Fail open
Change e Configuration Management
Una volta che il software sia stato rilasciato in ambiente di produzione, gli utenti richiederanno inevitabilmente l’aggiunta di nuove feature, la correzione di eventuali bug e altre modifiche al codice.
Così come è opportuno che un’organizzazione si strutturi con una adeguato percorso di progettazione, scrittura, test, sviluppo, correzione e manutenzione del software, altrettanto è opportuno che faccia per le configurazioni e le modifiche.
Ogniqualvolta vi sia una richiesta di variazione di configurazioni e specifiche, è opportuno che il processo sia gestito con una apposita modalità, che generalmente richiede una verifica della compatibilità e della fattibilità di quanto richiesto con il prodotto o il servizio; una analisi degli impatti della modifica (tempi e costi, ad es.), una analisi di eventuali implicazioni contrattuali unitamente all’individuazione delle responsabilità coinvolte, così come di un adeguato monitoraggio e rendicontazione delle modifiche.
L’approccio DevOps
Colmare le differenze che spesso si ritrovano tra diverse mentalità e competenze e riunire più conoscenze e punti di vista per una migliore gestione è lo scopo di questa metodologia: unire persone, processi e tecnologie nella pianificazione delle applicazioni, sviluppo, distribuzione e operazioni per consentire il coordinamento e la collaborazione tra ruoli precedentemente separati e divisi.
Le API
L’utilizzo di Application Programming Interface consente di far lavorare in modo appropriato diversi web services.
Tuttavia gli aspetti di sicurezza, soprattutto in relazione ai requisiti di autenticazione, non dovrebbero mai essere sottovalutati: le chiavi API sono come password e come tali dovrebbero essere trattate; si tratta di informazioni delicate e con un elevato grado di sensibilità.
Code repositories
Lo sviluppo di software è un arte collaborativa, che spesso viene eseguita con team che lavorano su parti differenti di un progetto.
Le repositories come GitHub, BitBucket, SourceForge sono utilissime, visto che forniscono version control, bug tracking, web hosting, release management e altro ancora.
E’ necessario, e non solo opportuno, che gli accessi a tali servizi siano gestiti con estrema attenzione, non solo per la segretezza che determinati progetti deve comportare ma anche per la pratica gestione delle chiavi API in server altrui.
SLA Service Level Agreements
E’ più di un saggio consiglio quello di utilizzare appropriati SLA contrattuali in ogni data circuit, applicazione, servizio o sistema di elaborazione o elemento critico che risulti vitale per una organizzazione.
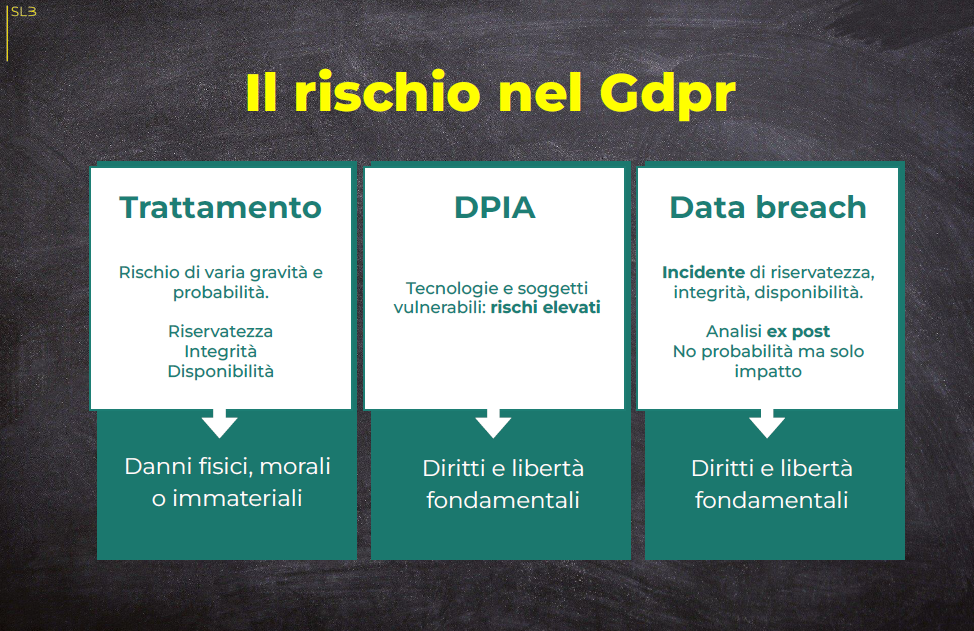
Sviluppare in conformità al Gdpr
Il software, sia nella fase di sviluppo e progettazione ma anche nelle successive, deve rispettare requisiti di business, che includono anche requisiti normativi, di “alto livello”; altri requisiti sono architetturali, di design, di user experience (e, quindi, di sistema). Di fatto si tratta di molti aspetti da tenere in considerazione.
Ma tutto ciò non basta, perché il software deve anche essere sicuro.
Tra le principali norme da rispettare vi è il Regolamento Europeo n. 679/2016 sulla protezione dei dati personali e la libera circolazione degli stessi dati.
Premesse
E’ essenziale garantire che tutti i dati degli interessati (utenti) e tutti i trattamenti siano protetti da adeguate misure di sicurezza tecniche e organizzative, sin dalla fase della progettazione e, successivamente, in quelle di utilizzo.
Consapevolezza
E’ necessario conoscere i principi e le regole della data protection; un ufficio o una persona incaricata, oltre all’eventuale DPO, sono di grande ausilio.
Mappatura e classificazione
Oltre ad essere spesso obbligatorio, il Registro delle attività di trattamento di cui all’art. 30 del Gpdr è un ottimo strumento per avere un quadro dettagliato ma anche generale dei trattamenti e delle relative caratteristiche, che si eseguono.
Analizzare i rischi
Oggigiorno è imperativo, oltre che necessario da un punto di vista normativo, comprendere, analizzare, ponderare e gestire il rischio relativo ai trattamenti, il rischio per i diritti e le libertà fondamentali delle persone, il rischio derivante da un eventuale incidente.
Misure organizzative, processi e procedure
Fare in modo che le procedure interne garantiscano la conformità alle norme è un ottimo strumento per assicurare il rispetto del principio di accountability.
Indicazioni sempre valide
Qui di seguito alcune indicazioni utili per gestire adeguatamente sia lo sviluppo sia la manutenzione e gestione di un applicativo, di un servizio, di un software.
Dati personali
Conoscere le definizioni di dato personale, dato direttamente o indirettamente identificativo, dati di carattere particolare (ex dati “sensibili”), dati biometrici, genetici è determinante in quanto alcuni di essi devono essere soggetti a particolari misure di protezione o devono e/o possono essere trattati solamente a determinate condizioni.
Anonimizzazione e Pseudonimizzazione
Si tratta di due diverse modalità di trattamento dei dati personali che hanno conseguenze diverse.
Allorché un dato sia stato sottoposto ad anonimizzazione (dato anonimizzato) e questa sia certa, la regolamentazione privacy non si applica più: è un procedimento irreversibile.
Il procedimento deve impedire l’individuabilità di un interessato sotto un triplice punto di vista:
- single out,
- linkability,
- inference.
Un dato pseudonimo, invece, è un dato che deve essere gestito e trattato secondo quanto previsto dal Gdpr, perché il procedimento è reversibile.
Un dato anonimo sin dall’origine non è un dato soggetto alle regole data protection.
Preparare il progetto
I principi della protezione dei dati personali devono essere integrati sin dalle fasi di progettazione.
La normativa intende proteggere le persone attraverso la protezione dei dati che le individuano e caratterizzano.
I requirements normativi devono essere inseriti sin dall’inizio dei lavori.
Da valutare, di volta in volta, se condurre una valutazione di impatto sui diritti e le libertà fondamentali degli interessati, che potrebbe tra l’altro essere richiesta dal Titolare a quei Responsabili che sono coinvolti nel trattamento proprio per l’affidamento, ad essi, di rilevanti funzioni di trattamento.
Metodologie di sviluppo sicure
L’adozione di una metodologia che consenta di includere le impostazioni privacy sin dal progetto, di avere il pieno controllo dei dati e dei sistemi, con un adeguato controllo delle versioni del codice, è imperativa.
Sicurezza dell’ambiente di sviluppo
La sicurezza dei server di produzione, sviluppo e integrazione, così come quella delle macchine di lavoro deve essere una priorità.
E’ necessario, oltre che valutare i rischi insiti nel trattamento relativo allo sviluppo, considerarli anche in relazione a tutti gli strumenti: adottare una politica che prescriva o vieti determinati comportamenti è vitale.
Va da sé che la gestione degli accessi e la tracciabilità delle operazioni sono essenziali: a partire dall’identificazione degli utenti, passando attraverso autenticazione e successive, granulari autorizzazioni, per giungere ad auditing, controllo e logging delle operazioni, deve essere un altro punto di impegno da rispettare.
Gestione e protezione del codice sorgente
Si sono già evidenziate modalità di protezione di asset aziendali quali, ad esempio, il codice sorgente.
Un’altra modalità di protezione è quella di prevedere dei Source Code Escrows, che consentano il “deposito” del codice sorgente presso soggetti fiduciari.
E’ essenziale mantenere una cronologia di tutte le modifiche apportate e, come già detto, utilizzare un modello di sviluppo sicuro e affidabile.
Componenti di terze parti
Il frequente, utile e importante utilizzo di librerie, SDK o altri componenti software di terze parti, deve essere inserito nel disegno progettuale secondo regole precise e definite.
Oltre a valutare il peso di ciascuna dipendenza da tali componenti, che ovviamente aumenta anche la superficie di esposizione al rischio, è opportuno scegliere soluzioni e software che non si ripaghino con l’utilizzo dei dati presenti nelle applicazioni in cui sono integrati e, ovviamente, seguirne i mutamenti, le evoluzioni e gli sviluppi, anche di sicurezza.
Architettura e scelte
Progettando l’architettura di una applicazione è importante conoscere il ciclo di vita dei dati personali che verranno raccolti e trattati.
Gli asset di supporto sono fondamentali.
Se, come spesso avviene, si scelgono fornitori di servizi esterni, è necessario optare per provider conosciuti e possibilmente verificarne le certificazioni, oltre che esaminare la documentazione contrattuale di riferimento.
Un altro aspetto certamente da considerare è quello relativo al posizionamento dei server all’interno o meno dello Spazio Economico Europeo ma, soprattutto, della nazionalità del fornitore.
Nel caso di trattamenti di dati personali di carattere particolare (sanitari), è opportuno prevedere particolari misure di attenzione e sicurezza.
Proteggere i siti web, le applicazioni, i server
La protezione e la sicurezza delle reti di comunicazione (protocolli, porte, ecc.) è essenziale, così come è necessario implementare procedure di autenticazione forte (MFA).
La gestione delle autenticazioni è essenziale: oltre al fatto che le password non dovrebbero mai essere conservate se non crittografate, è necessario prevedere specifiche policy per gli amministratori di sistema così come limitare l’accesso alle interfacce di amministrazione solo a personale qualificato.
Tutta l’infrastruttura deve essere controllata regolarmente.
Tenere a mente i principi privacy
Per impostazione predefinita:
- trattare la minima quantità di dati personali, ossia solo quelli strettamente necessari alle finalità per le quali sono richiesti;
- trattarli solo ed esclusivamente per le finalità definite;
- stabilire e rispettare un termine di conservazione adeguato e tendenzialmente il più breve possibile;
- prevedere un sistema di cancellazione, dove possibile automatica, dei dati al termine del trattamento (salve necessità o possibilità di anonimizzazione).
Queste misure possono essere raggruppate mediante opzioni di configurazione che consentono di gestire i criteri di cui sopra dal “proprietario” della soluzione, direttamente dall’utente dal proprio account o da un apposito pannello.
Informare gli utenti
Fornire adeguate, pertinenti, esaustive ma concise, trasparenti, comprensibili e facilmente accessibili informazioni è un obbligo “forte” del Gdpr e non deve mai essere dimenticato.
Tenere conto che i dati possono essere raccolti direttamente dall’interessato o ricevuti da terzi, con alcune necessità ulteriori.
Basi giuridiche e diritti
Tenere conto della base giuridica che legittima il trattamento dei dati è fondamentale: alcuni trattamenti di dati personali sono effettuati a motivo della necessità di concludere un contratto oppure di eseguirlo e gestirlo.
Determinati trattamenti sono effettuati perché una norma o un obbligo li impongono.
Altri ancora hanno come “giustificazione” il c.d. “legittimo interesse”, il quale peraltro deve avere determinate caratteristiche, come ad esempio prevalere sui diritti e gli interessi dell’utente.
In altri casi è la natura dell’attività esercitata dall’ente che legittima il trattamento, come l’esecuzione di un compito di interesse pubblico o l’esercizio di pubblici poteri.
Solo in alcuni casi il trattamento è eseguito perché l’interessato ha prestato il proprio consenso. E’ necessario rammentare, e quindi progettare il servizio, di modo che l’interessato possa revocare il proprio consenso liberamente (senza pregiudizio per i trattamenti eseguiti in precedenza), in qualsiasi momento.
Sviluppare e gestire l’esercizio dei diritti degli interessati
Proprio per quanto appena detto, è indispensabile “pensare” al progetto e gestirlo tenendo conto dei tanti e diversi diritti che le persone hanno in relazione ai propri dati.
Prevedere funzionalità apposite sin dalla progettazione è determinante.
I cookie e gli analytics
Il 10 giugno 2021 il Garante della Privacy ha pubblicato delle nuove Linee Guida in materia di cookie e altri strumenti di tracciamento.
Le Linee Guida vogliono far cessare la spesso indiscriminata pervasività degli strumenti utilizzati per creare “profili” sempre più accurati. Tutti noi navighiamo ogni giorno con diversi strumenti e per il tramite di plurimi servizi e molteplici funzioni.
Ciò consente l’incrocio di dati personali da molte fonti (c.d. “enrichment”) da cui deriva una spesso esagerata profilazione di persone, abitudini, gusti, bisogni, preferenze.
Le nuove regole tendono a fornire maggiori tutele, più controllo e una reale possibilità di scelta per gli utenti:
regolano le operazioni di lettura e di scrittura all’interno del terminale di un utente, con specifico riferimento all’utilizzo di cookie e di altri strumenti di tracciamento;
le corrette modalità per la fornitura dell’informativa e per l’acquisizione del consenso on-line degli interessati.
Valgono sia per gli identificatori attivi, siano essi di prima o di terza parte, sia per quelli passivi, come ad esempio il fingerprinting.
Le regole, molto in sintesi, prevedono che i cookie tecnici possano essere installati liberamente mentre tutti i cookie non strettamente necessari alla navigazione debbano essere sottoposti alla regola del consenso, libero, informato, consapevole e documentato.
Per quanto riguarda i cookie analitici (analytics) essi possono essere considerati tecnici solo se non consentono la diretta individuazione dell’interessato (cd. single out). Lo sono, dunque, solo quelli che consentono o permettono:
- Misurazione delle performance,
- Rilevazione problemi nella navigazione,
- Ottimizzazione performance tecniche,
- Stima potenza dei server,
- Analisi dei contenuti consultati, ecc..
Google Analytics
Un noto provvedimento del Garante, reso relativamente al tracciante GA_3, ne ha dichiarato l’illiceità dell’utilizzo.
In sintesi:
- l’indirizzo IP costituisce un dato personale nella misura in cui consenta di identificare un dispositivo, rendendo indirettamente identificabile l’interessato/utente;
- l’opzione “IP-Anonymization” messa a disposizione da Google consiste non in una anonimizzazione, bensì in una pseudonimizzazione dell’indirizzo IP, in quanto il troncamento dell’ultimo ottetto non impedisce a Google LLC di re-identificare l’utente, considerato che Google detiene ulteriori informazioni relative agli utenti;
- l’utilizzo di GA, da parte dei gestori dei siti web comporta, quindi, il trasferimento dei dati personali degli utenti verso Google LLC con sede negli Stati Uniti;
- nonostante fossero state sottoscritte le SCCs, in assenza di misure supplementari, il Garante dichiara l’illiceità dei trasferimenti;
- nonostante l’adozione della cifratura in transit e at rest le misure non risultano adeguate ad evitare i rischi di un accesso, ai fini di sicurezza nazionale, ai dati trasferiti dall’UE da parte delle Autorità locali, perché le tecniche di cifratura adottate prevedono che la disponibilità della chiave di cifratura sia in capo a Google LLC;
- fintanto che la chiave di cifratura rimanga nella disponibilità dell’importatore, le misure adottate non possono ritenersi adeguate;
- le valutazioni sono in capo al titolare e l’informativa deve contenere informazioni sui trasferimenti sulle relative garanzie appropriate.
Google dichiara che la versione GA_4 sia differente.
Diversi esperti hanno rilevato come non sia vero che con la versione GA4 risolva la questione, né che il provvedimento sanzionatorio dell’Autorità colpisca solo la versione gratuita senza l’oscuramento dell’IP utente.
La “mascheratura” di parte dell’indirizzo IP costituisce una pseudonimizzazione, ma il Gdpr rimane applicabile (con la mascheratura il dato non “diventa” anonimo). In ogni caso Google ha strumenti e mezzi tali per consentire la reidentificazione.
Non è nemmeno vero che il provvedimento sia “ristretto” ai soli utenti che si siano previamente loggati tramite Google e che, se così non fosse, Google non potrebbe reidentificare l’utente.
Al di là del fatto che non si vede come il “sito” possa verificare se l’utente si sia già loggato sui servizi Google, il problema non è spostato: l’estensione dei servizi è tale per cui è possibile per Google, astrattamente, reidentificarlo.
Il fatto che Google abbia in essere Clausole contrattuali standard non è sufficiente, nemmeno considerando le ultime SCCs disponibili: è necessario che gli operatori provvedano secondo le Raccomandazioni dell’EDPB, di fatto procedendo al c.d. Transfer impact Assessment (oltre che alle altre indicazioni), per cui è il Titolare a dover documentare il proprio processo di compliance nello specifico; ciò che risulta alquanto improbabile possa essere fatto.
Il problema non è spostato né scalfito dal fatto che il rapporto sia in essere con Google Ireland, per le note ragioni di possibile ingerenza della casa madre statunitense sulle aziende USA, le cui “succursali” europee soggiacciono alle norme sulla vigilanza americana.
Insomma: la questione è ancora aperta.
L’indirizzo Ip è dato personale?
Altra questione sempre attuale è la risposta a questa domanda.
Le Autorità ritengono, alla lettera, che se l’indirizzo IP consente l’identificabilità è, conseguentemente, un dato personale.
Una recente sentenza stabilisce, in parte, diversamente.
Si tratta di una sentenza estremamente interessante, perché, di fatto, implica considerazioni di vasta portata non solo sul concetto di dato personale ma anche di trasferimento dei dati e di necessità normative.
In sostanza stabilisce che bisogna considerare la posizione del ricevente i dati: se costui non ha gli strumenti e i mezzi (pure in possesso del trasmittente), per individuare gli interessati, non deve applicare la normativa sui dati personali.
Ad ogni modo molti esperti del settore concordano sul fatto che, da solo, un indirizzo IP, nella migliore delle ipotesi, e non sempre, identifichi “una macchina o meglio un sistema (PC, Server, Stampante, Disco di Rete, Router, qualunque cosa). Di per sé l’indirizzo IP non ci dice nulla della “persona” (fisica!) dietro al o ai sistemi; quando una persona c’è! (v. IoT, domotica ed altro).”
Giugno 2023
